
Thanks to everyone who emailed me in that they completed or had questions about the mini forensics challenge, I’m glad that someone out there reads this blog 😉 Here are the answers below. I used Hex Editor Neo in the screenshots.
Challenge 1: Using a hex editor, repair this zip file which has had its header and footer corrupted.
Some reading on the articles at the bottom of the original blog page will have led you to realise that zip files start with the bytes 0x04034b50 (read as a little-endian number) and have an ‘end of central directory record’ (I will call this the end block) which start with the bytes 0x06054b50 (also little-endian). Little Endian means this has to be read in reverse byte order (right to left); i.e. for the start you are looking for the sequence 50-4b-03-04. Subsequently, big-endian means bytes are read left-to-right, i.e. the way we would expect to read bytes: 04-03-4b-50. Opening up the corrupted zip file in a hex editor shows that the 1st two bytes of the start and end block have been altered to 51-4c. Changing these back to 50-4b and saving the file fixes the zip file.
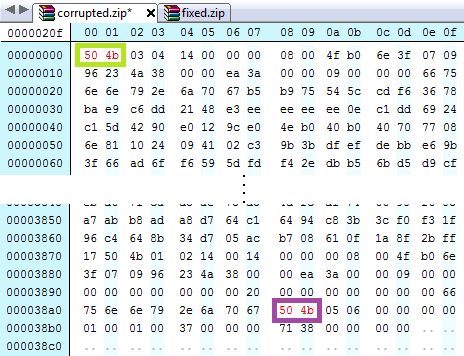
The start (green) and end bytes (purple) of the zip file which need to be altered.
Challenge 2: Somewhere inside this file is a zip file. Can you carve out the zip file?
Now we know what headers and footers to look for, we can do a search inside badcluster to find starting bytes. Badcluster has two potential starting bytes. Searching for an end block we find one. According to the zip file specification, the end block for zip files is at a minimum 22 bytes long, with the final byte(s) being a comment. If we start counting from 0 at the start of the end block, at byte 22 we find a 00. We can confirm there is no comment by looking at byte 20; this states the size of the comment, which is also 00. If this was not 00, we would have the count the extra number of bytes for the comment length to reach the end of the file. We have two starting blocks, so both can be tested by copying all the bytes from the start of the start block to the end byte we have just identified. The results for the second starting block work: when we copy bytes from 000000a8 to 00003965 from badcluster we get a zip file.

The two potential starts of zip files (yellow).
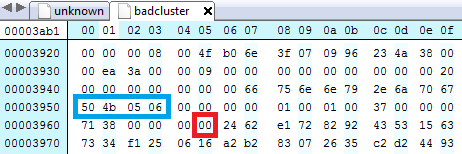
The start of the End of Central Directory Record (blue) and the final byte of the zip file (red).
I hope these answers make sense, please post any questions in the comments below!
